[Cloudflare] Hyperdriveを学ぶ:WorkersとSupabaseをつなぐプロキシの仕組み
![[Cloudflare] Hyperdriveを学ぶ:WorkersとSupabaseをつなぐプロキシの仕組み](/assets/note/eyecatch/cloudflare-hyperdrive-with-supabase-eyecatch.png)
illustrated by soto
きっかけ
Cloudflare WorkersでSupabaseを使おうとしていたときに、「Workers × Supabaseには相性問題がある」という記事に出会った。さらに、別の筆者によるこちらの記事で、その解決策として Cloudflare Hyperdrive が紹介されていた。
問題の核心は 「WorkersはIPが固定されないので、Supabase側でIP制限がかけられない」 こと。名前は聞いたことがあっても、何をするものなのかよくわかっていなかったので、改めて調べてまとめた。
Hyperdriveとは
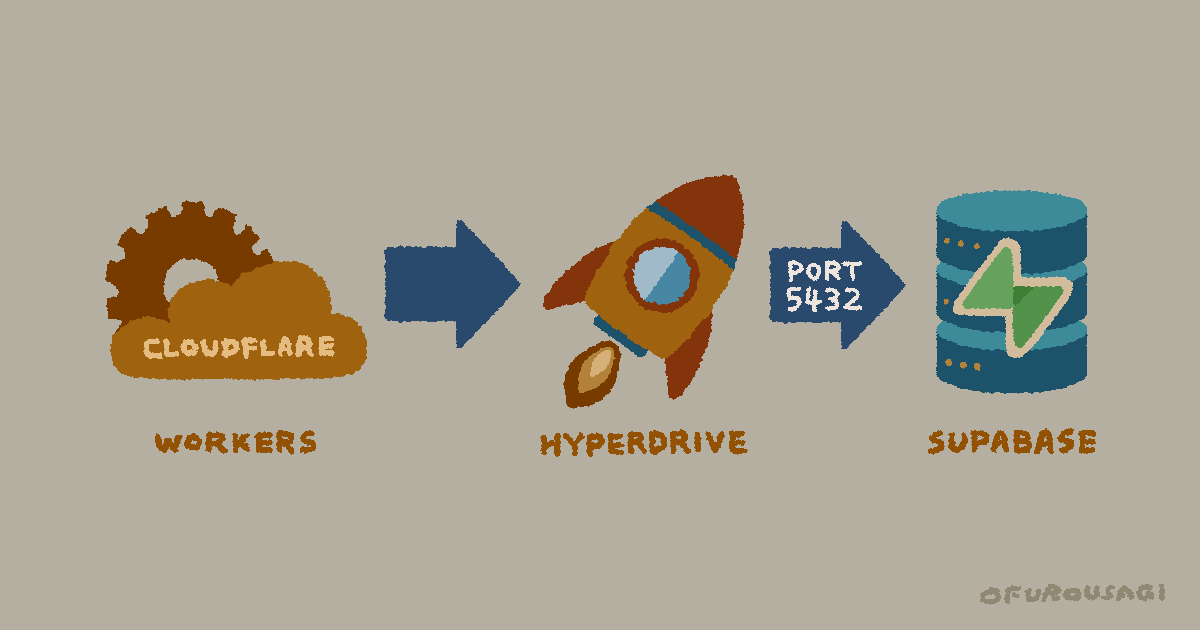
Cloudflareが提供する データベースプロキシサービス。2024年4月1日に正式リリースされ、WorkersとDBの間に挟んで使う。
We kick off the week with announcements that help developers build stateful applications on top of Cloudflare, including making D1, our SQL database and Hyperdrive, our database accelerating service, generally available. https://t.co/Skdq9cVvwZ #DeveloperWeek
— Cloudflare (@Cloudflare) April 1, 2024
日本語訳: 今週は、Cloudflare上で開発者がステートフルなアプリケーションを構築するのに役立つ発表からスタートします。これには、CloudflareのSQLデータベースであるD1と、データベース高速化サービスであるHyperdriveの一般提供開始が含まれます。
公式の説明は「既存のリージョナルDBをグローバル分散DBに変える」というもので、PostgreSQLに正式対応している(MySQLはbeta)。リージョナルDB(特定の地域のデータセンターに置かれたDB)を、エッジ経由でどこからでも高速に使えるようにするイメージ。既存のORMやドライバをほぼそのまま使えるのも特徴。
Supabaseとの組み合わせでは次のような構成になる。
なぜ必要か:Workersの2つの問題
問題1:IPが固定されない(セキュリティ)
Workersは世界中のエッジノードで動くため、DBへの接続元IPが毎回変わりうる。SupabaseのDirect ConnectionにはIP制限機能があるものの、接続元IPが毎回異なると実質的に使えない。
Hyperdriveを経由すると CloudflareのIPレンジからの接続になるため、Supabase側でIP制限が設定できるようになる。

※図中のIP値は説明用のダミー。実際はCloudflareの公開IPレンジ全体を前提に設定する。
ただし、これは「固定IP」ではなく、あくまで「CloudflareのIPレンジ内」に限定されるという意味にすぎない。CloudflareのIPレンジは公開されており範囲も広いため、厳密なIP制限とは言いづらい。それでも、WorkersからのDB接続元が全インターネットに開放される状態に比べれば、実用上のリスクは大きく下げられる。
問題2:接続が毎回作られる(パフォーマンス)
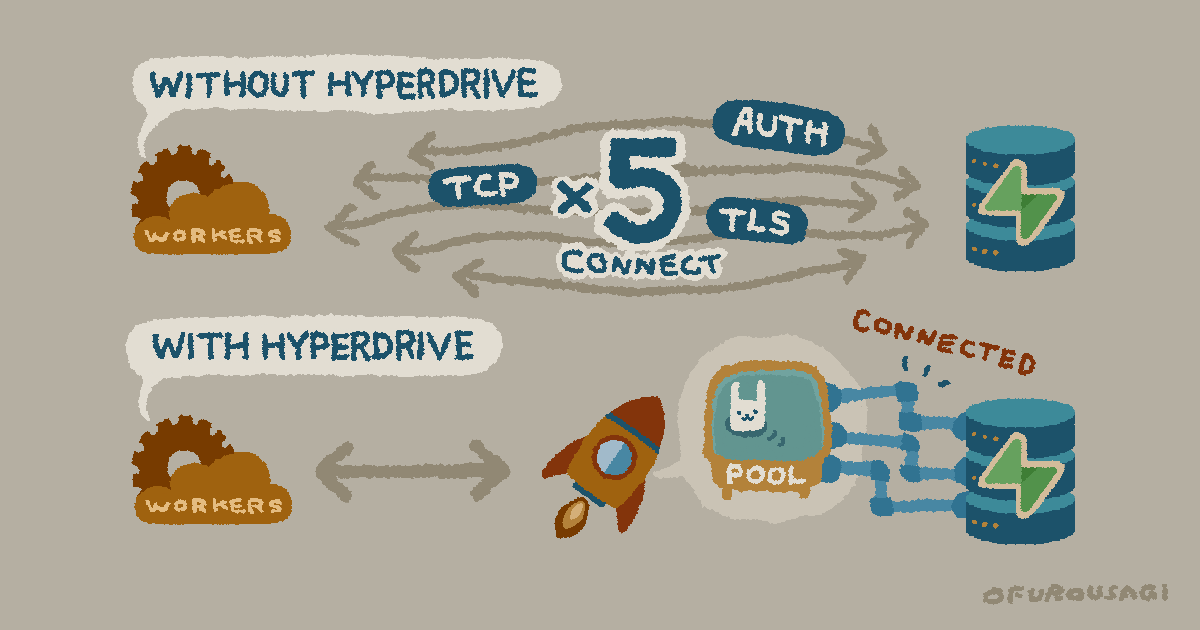
Workersはリクエストごとに短時間で実行されるため、素朴に実装するとDBへの接続が毎リクエストごとに張られてしまう。接続確立は重い処理なので、これがボトルネックになる。
Hyperdriveは接続を使い回す(プーリング / Pooling)ことで、このコストを削減する。
Hyperdriveの仕組み
コネクションプーリング(Connection Pooling)
Hyperdriveなしの場合、Workerが呼び出されるたびに複数回のラウンドトリップ(往復通信)が発生し、その後でないとクエリを実行できない。TLS 1.3・新規接続・典型的な認証の場合の目安は以下の通り。
| ステップ | 往復数 | 内容 |
|---|---|---|
| TCPハンドシェイク | × 1 | TCP(Transmission Control Protocol)。信頼性のあるデータ通信を実現するプロトコル。SYN / SYN-ACK / ACKの3ステップで接続を確立する |
| TLSネゴシエーション | × 1 | TLS(Transport Layer Security)。通信を暗号化するプロトコル。現在主流のTLS 1.3では鍵交換が改善され1往復で完了する(旧TLS 1.2では最大3往復) |
| DB認証 | × 1〜3 | データベースへのログイン処理。認証方式による(SCRAM-SHA-256は最大3往復、MD5は1〜2往復) |
| 合計(目安) | 最大 × 5 程度 |
- SYN(Synchronize):クライアントが「接続したい」と要求を送る
- SYN-ACK(Synchronize-Acknowledge):サーバーが「了解、こちらも準備OK」と応答する
- ACK(Acknowledge):クライアントが「確認した」と返して接続が確立される
TLSのバージョンは接続時に自動でネゴシエーションされ、ユーザーが選ぶものではない。現在のSupabase(PostgreSQL 15〜16)とHyperdriveはTLS 1.3に対応しているため、上記が実態に近い内訳。ただし、TLSセッション再利用(0-RTT)時やDB認証方式によって往復数は変動する。
Hyperdriveがコネクションプーリングで解決する問題は、往復数の削減だけではない。主なメリットは次の2つ。
① 接続のコールドスタートを排除する
HyperdriveはCloudflareのネットワーク内にDB接続のプールを維持し、接続セットアップをエッジ(WorkerとHyperdrive間)とオリジン(HyperdriveとDB間)の2段階に分ける。WorkerからHyperdriveまではCloudflare内部ネットワークで低遅延、Hyperdrive〜DB間の接続はあらかじめ確立済みのものを再利用する。
通常:Worker → [TCP + TLS + DB認証 = 最大5往復程度] → DB → クエリ実行
Hyperdrive:Worker → Hyperdrive(エッジ、低遅延)
↓ 既存接続を再利用
Hyperdrive → DB → クエリ実行
TLS 1.3では往復数は5回程度に減るが、WorkerとDBが地理的に離れている場合(例:Worker=米国、DB=東京)は1往復でも100ms以上かかる。コールドスタートを丸ごと排除できるのがHyperdriveの本質的な価値。
② DB側の接続数を守る
Workersは同時に何千ものリクエストを処理できる。Hyperdriveなしだと、それだけの数のDB接続が同時に張られる可能性がある。Supabase Freeプランは同時接続60本が上限のため、あっという間に枯渇する。Hyperdriveがプールを介してDB側の接続数を絞ることで、この問題を回避できる。
トランザクションモード(Transaction Mode) で動作するため、トランザクションの実行中は1つの接続を占有し、終了後にプールへ返却される。HyperdriveへのWorkers側の接続数(クライアント側)に制限はなく、DB側の接続数がボトルネックになりやすい。Supabase Freeプランは同時接続60本が上限なので注意。
プールの接続数は最小5接続から、Workersプランに応じた上限までの範囲で管理される。max_sizeはソフトリミットとして機能するため、ネットワーク問題やトラフィック急増時には一時的に上限を超えることがある。
接続がプールに返却されると RESET が実行され、その接続で設定したSET文の内容はすべてクリアされる。SETで変更したセッション設定(タイムゾーンなど)はリクエストをまたいで引き継がれないため、必要ならクエリやトランザクションごとに再設定する必要がある。
クエリキャッシュ(Query Cache)
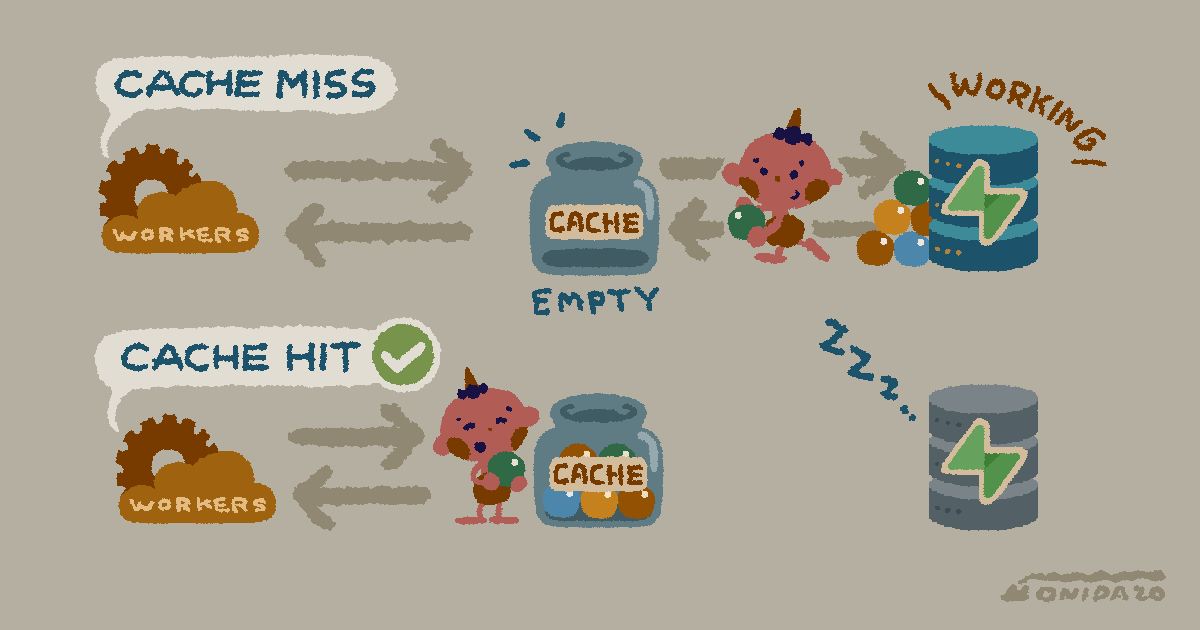
SELECTクエリのうち、キャッシュしても安全なものを自動でキャッシュしてくれる。DBまでクエリが飛ばないため、高速化が見込める。
クエリの結果がすでにキャッシュにある状態を キャッシュヒット、ない状態を キャッシュミスと呼ぶ。ヒット時はDBへの問い合わせが発生せず即座に返却される。ミス時はDBまで問い合わせに行き、返ってきた結果をキャッシュに保存する。
キャッシュされる条件
キャッシュされるのは 読み取り専用かつパラメータ化されたクエリに限られる。パラメータ化とは、値をSQL文に直接埋め込まず$1・$2などのプレースホルダーで渡す書き方のこと。
-- ✅ キャッシュされる(パラメータ化)
SELECT * FROM products WHERE id = $1
-- ❌ キャッシュされない(値の直埋め込み)
SELECT * FROM products WHERE id = 42また、使用している関数が IMMUTABLE(同じ入力に対して常に同じ値を返す)であることも条件になる。
キャッシュされない条件
PostgreSQLの関数は「どれだけ結果が変わりやすいか」で3種類に分類される。HyperdriveはIMMUTABLE以外の関数を含むクエリをキャッシュしない。
| 分類 | 特徴 | 例 | キャッシュ |
|---|---|---|---|
| IMMUTABLE | 同じ入力なら常に同じ結果 | lower()、length() |
✅ される |
| STABLE | 同一トランザクション内では同じ結果だが変わる可能性あり | NOW()、CURRENT_TIMESTAMP、CURRENT_DATE |
❌ されない |
| VOLATILE | 呼び出すたびに結果が変わる可能性あり | RANDOM()、LASTVAL()、TIMEOFDAY() |
❌ されない |
また、以下もキャッシュ対象外となる。
INSERT/UPDATE/DELETE/CREATE TABLEなどの変更クエリ(DBプロトコルで自動判別)- SQLの コメント内に関数名が含まれるだけでもキャッシュ不可と判定される
-- ❌ コメントに NOW が含まれるだけでキャッシュ不可
-- get records created after NOW()
SELECT * FROM events WHERE created_at > $1NOW()やCURRENT_DATEをクエリ内で使いたい場合は、アプリケーション側で現在時刻を取得してパラメータとして渡すとキャッシュを活かせる。
// ✅ アプリ側で現在時刻を取得してパラメータ渡し
const now = new Date()
const result = await client`SELECT * FROM events WHERE created_at > ${now}`キャッシュの設定
wrangler.tomlの[[hyperdrive]]セクションに設定を追記できる。
[[hyperdrive]]
binding = "HYPERDRIVE"
id = "<発行されたID>"
caching = { max_age = 60, stale_while_revalidate = 15 }max_age:キャッシュの有効期間(秒)。デフォルト60秒、上限3600秒(1時間)stale_while_revalidate:有効期限切れ後もこの秒数の間は古いキャッシュを返しつつバックグラウンドで更新する。デフォルト15秒
キャッシュを無効化する
開発中やデバッグ時などにキャッシュを無効化したい場合は、別のHyperdrive設定を用意し、caching-disabledオプション付きで作成する。
npx wrangler hyperdrive create my-hyperdrive-no-cache \
--connection-string="postgres://..." \
--caching-disabled本番用とキャッシュ無効用の2つをバインドしておき、用途に応じて使い分けるパターンが使いやすい。
固定IPレンジ
前述の通り、HyperdriveからDBへの接続元はCloudflareのIPレンジに限定される。これにより、DB側のIP制限が機能しやすくなる。
Placement
1リクエストで複数の連続したクエリを実行する場合は、Placementを使ってWorkerをDBの近くで動作させると遅延を抑えられる。クエリごとにラウンドトリップの遅延が加算されるため、クエリ数が多いほど差が大きくなる。
- 遠いリージョンから実行:1クエリあたり約20〜30msの往復遅延
- DBの近くに配置:1クエリあたり約1〜3msの往復遅延
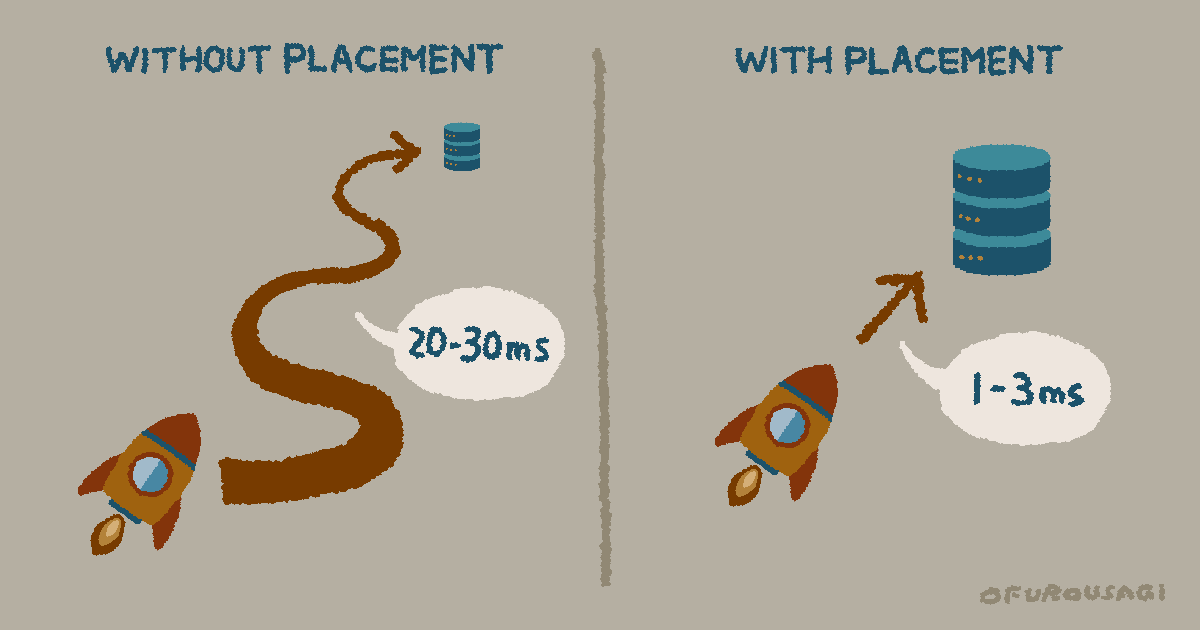
1リクエストにつきクエリが1つだけなら、Placementによるエンドツーエンドの遅延改善はほぼない。
設定はwrangler.tomlにplacementセクションを追記する。DBのリージョンが分かっているならregionを指定する。複数のバックエンドを使う場合や配置先が不明な場合はmode = "smart"を使う。
[placement]
region = "aws:ap-northeast-1" # Supabase の場合は該当リージョンに合わせるセットアップ手順
1. Hyperdriveを作成する
npx wrangler hyperdrive create my-hyperdrive \
--connection-string="postgres://USER:PASSWORD@HOST:5432/postgres"接続文字列はSupabaseダッシュボードの「Database」→「Connection string」→「Direct connection」から取得する。
Hyperdrive の接続先には db.<project-ref>.supabase.co:5432 の Direct connection を使うこと。
- Direct接続:
db.<project-ref>.supabase.co:5432に直接つなぐ接続 - Supavisor Session mode:
*.pooler.supabase.com:5432を使う共有プーラー - Supavisor Transaction mode:
*.pooler.supabase.com:6543を使う共有プーラー
Supabase では 5432 番が常に Direct connection とは限らない。Session mode も 5432 番を使うため、ポート番号だけでなくホスト名も確認する のが重要。
HyperdriveがプーリングをするためSupavisorと二重にすると問題が起きる(詳しくは後述の注意点参照)。
コマンドが成功するとHyperdriveのIDが発行される。
2. wrangler.tomlに追記する
compatibility_date = "2026-02-13" # 2024-09-23以降が必要
compatibility_flags = ["nodejs_compat"] # DBドライバの動作に必須
[[hyperdrive]]
binding = "HYPERDRIVE"
id = "<発行されたID>"3. Workersのコードから使う
Cloudflare はpgを推奨しているが、ここでは公式ドキュメントにも例があるpostgres(postgres.js)を使う。DrizzleなどのORMを使う場合は、その上に載せればよい。
import postgres from "postgres"
export default {
async fetch(request: Request, env: Env) {
// リクエストハンドラ内で初期化(グローバルスコープはNG)
const client = postgres(env.HYPERDRIVE.connectionString, {
max: 5,
prepare: true,
})
const result = await client`SELECT * FROM some_table`
return Response.json(result)
},
}env.HYPERDRIVE.connectionStringで接続文字列が取れる。あとは通常のDB接続と同じように使える。
実装時の注意点

1. prepareをむやみに無効化しない
Supavisor の Transaction mode では Prepared Statement を無効化する必要があるが、Hyperdrive は postgres.js と node-postgres の名前付き Prepared Statement をサポートしている。postgres.js では prepare: true が既定値なので、そのまま使ってよい。prepare: false にすると Hyperdrive のキャッシュが効きにくくなり、余分なラウンドトリップも発生する。
// ❌ Hyperdrive 経由でわざわざ無効化する必要はない
const client = postgres(env.HYPERDRIVE.connectionString, {
prepare: false,
})
// ✅ 既定値の true のまま使う
const client = postgres(env.HYPERDRIVE.connectionString)Kyselyやsql.unsafe()など、内部的にprepare: falseになるケースでは Hyperdrive のキャッシュ特性が変わる点に注意する。
2. DBクライアントはハンドラー内で作成する
グローバルスコープとは、リクエストハンドラ(fetch関数)の外側、つまりファイルのトップレベルに書かれたコードのこと。Workersでは同じインスタンスが複数のリクエストを処理するため、グローバルスコープの変数はリクエスト間で共有される。これにより、古い接続が意図せず再利用されてエラーが間欠的に発生する。
// ❌ NG:グローバルスコープで初期化
const client = postgres(env.HYPERDRIVE.connectionString)
export default { fetch: handler }
// ✅ OK:リクエストハンドラ内で毎回初期化
export default {
async fetch(request: Request, env: Env) {
const client = postgres(env.HYPERDRIVE.connectionString)
// ...
},
}なお、client.end()の明示的な呼び出しは不要。リクエスト終了時にHyperdriveが自動でクリーンアップする。オリジンDBへのプール接続は再利用のために維持される。
3. Hyperdriveの接続先にSupavisorを使わない
Hyperdrive 自体が接続プーリングを行うため、接続先に Supavisor を指定する必要はない。Hyperdrive の接続先は db.<project-ref>.supabase.co:5432 の Direct connection にする。特に Transaction mode(6543番)をさらに噛ませると、二重プーリングになり Prepared Statement 周りの制約も増える。
❌ Workers → Hyperdrive → *.pooler.supabase.com:5432 / :6543 → Supabase
✅ Workers → Hyperdrive → db.<project-ref>.supabase.co:5432
4. Durable Objectsは使い終わった接続を閉じる
通常のWorkerと異なり、Durable Objectsは複数のリクエストをまたいで状態を維持できる。DBクライアントを開いたままにすると、Hyperdriveの接続プールから接続が確保され続ける。多数のDurable Objectsが同時に接続を保持するとプールが枯渇する可能性があるため、使用後は接続を閉じ(client.end()を明示的に呼び出す)、接続タイムアウトも設定しておく。
5. トランザクションは短く保つ
Hyperdriveはトランザクションモードのプーラーなので、トランザクションが完了するまで接続が占有される。長時間のトランザクションはプール内の接続を長く拘束し、他のWorkerが接続を再利用できなくなる。トランザクションはできるだけ短く保つのが原則。
制限値まとめ
| 項目 | Free | Paid |
|---|---|---|
| DBの最大設定数 | 10個/アカウント | 25個/アカウント |
| オリジンへの最大接続数 | 約20 | 約100 |
| 最大クエリ実行時間 | 60秒 | 60秒 |
| キャッシュ最大サイズ | 50MB | 50MB |
Hyperdrive は Workers Free / Paid の両プランに含まれている。Free は 1 日 100,000 クエリまで、Paid はクエリ数無制限。接続プーリングとクエリキャッシュに追加料金はかからない。
まとめ
HyperdriveはWorkersとDBの間に挟むプロキシで、主に3つの役割を担う。
- IPレンジの限定 → CloudflareのIPレンジからの接続に絞られるため、SupabaseのIP制限が実用上機能する(厳密な固定IPではない点に注意)
- コネクションプーリング → 接続のコールドスタート(TCP + TLS + DB認証で最大5往復程度)を排除し、毎リクエストの接続コストを削減
- クエリキャッシュ → 安全なSELECTを自動でキャッシュ
Cloudflare 公式ドキュメントでも、Supabase と接続する構成例として Hyperdrive が案内されている。実装時は以下の5点を押さえておく。
prepareを無効化しない(postgres.js/pgは対応)- DBクライアントはリクエストハンドラ内で作成する(
client.end()は不要) db.<project-ref>.supabase.co:5432の Direct connection に向ける(Supavisorを挟まない)- Durable Objectsは使い終わった接続を閉じる
- トランザクションは短く保つ
複数クエリを1リクエストで実行する場合は、PlacementでWorkerをDBの近くに配置すると遅延をさらに削減できる。